L’A/B testing pour débutants et les pros
a/b Testing – Malgré tout le contenu disponible sur le sujet, les gens continuent à mal l’exploiter. Du mauvais choix de tests à l’exécution incorrecte d’A/B testing, il existe de nombreuses façons de se tromper.
SOMMAIRE
- Qu’est-ce que le test A/B ?
- Comment améliorer les résultats de tests A/B ?
- Comment prioriser les hypothèses de tests A/B ?
- Comment de temps faire durer les tests A/B ?
- Comment lancer des tests A/B ?
- Comment analyser les résultats de tests A/B ?
- Comment archiver les tests A/B précédents ?
- Statistiques d’A/B testing
- Outils et ressources pour l’A/B testing
- Conclusion
Qu’est-ce que l’A/B testing ?
L’A/B testing divise le trafic en 2 entre un témoin et une variante. Le test A/B est un nouveau terme pour une vieille technique – l’expérimentation contrôlée.
Lorsque les chercheurs testent l’efficacité de nouvelles drogues, ils utilisent un « split test » (test de division). En fait, plus de recherches expérimentales pourraient considérer le « split test », en associant une hypothèse, un témoin, une variante et un résultat calculé statistiquement.
Par exemple, si vous lancez un simple A/B test, il s’agira d’une simple division 50/50 du trafic entre la page originale et une variante :
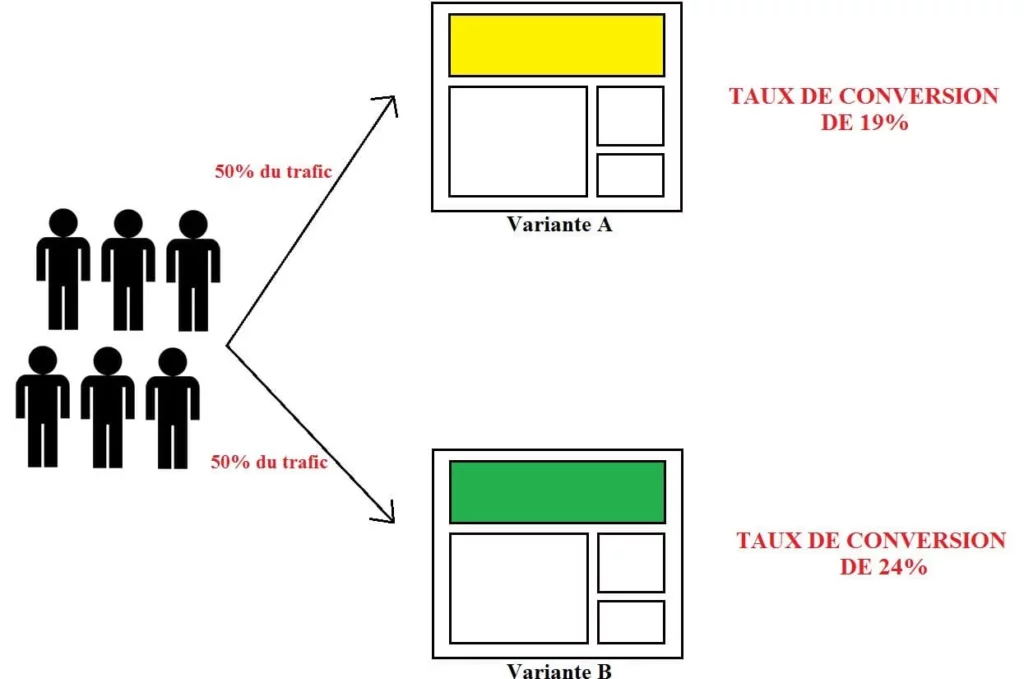
Pour le CRO, la principale différence est la variabilité du trafic sur Internet. Dans un labo, il est plus facile de contrôler des variables externes. Online, vous pouvez les nuancer, mais il est difficile de créer un test purement contrôlé.
En plus, le test de nouvelles drogues nécessite un degré de précision certain. Des vies sont en jeu. En termes techniques, votre période « d’exploration » peut être plus longue, comme vous voulez être complètement sûr de ne pas avoir une erreur.
Notre objectif est simple : rendre votre site plus engageant pour vos visiteurs. Nous combinons AB testing et analyse détaillée pour identifier et implémenter des améliorations concrètes sur votre site Web.
En ligne, le process de division de l’A/B testing considère des objectifs commerciaux. Il mesure le risque vs la récompense, l’exploration vs l’exploitation, les sciences vs le business. Par conséquent, nous regardons les résultats à travers différents objectifs et prenons des décisions différemment que celles que nous prendrions lors de tests en labo.
Vous pouvez, bien sûr, créer plus de 2 variantes. Les tests avec plus de deux variantes sont connus comme des tests A/B/n. Si vous avez suffisamment de trafic, vous pouvez tester autant de variantes que vous le souhaitez. Ci-dessous un exemple pour un test A/B/C/D, et combien de trafic est alloué à chaque variante :
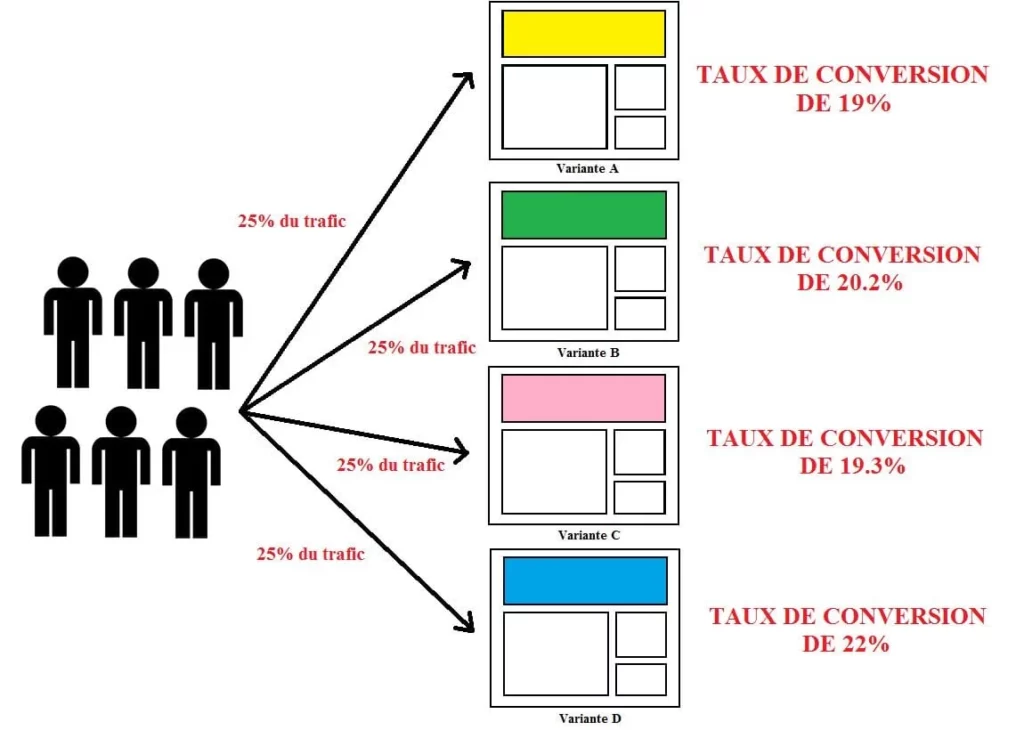
Les tests A/B/n sont très bien pour l’implémentation de plus de variantes d’une même hypothèse, mais ils nécessitent plus de trafic car ils le divisent entre plusieurs pages.
Les tests A/B, bien que plus populaires, sont seulement un type d’expérimentation web. Vous pouvez aussi lancer des test multivariés et des tests bandits (ou tests d’allocation dynamique de trafic).
A/B Tests , tests multivariés et tests bandits : quelle différence ?
Les tests A/B/n sont des expériences contrôlées qui lancent une ou plus variantes contre la page originale. Les résultats comparent les taux de conversion parmi les variantes, lesquelles sont définies par un simple changement par rapport à la page témoin.
Les tests multivariés testent des versions multiples d’une page pour isoler l’élément qui a le plus d’impact. En d’autres termes, ce sont comme des tests A/B/n dans le sens où ils permettent de tester un témoin contre des variantes, mais chaque variante contient des éléments de design différents. Par exemple :
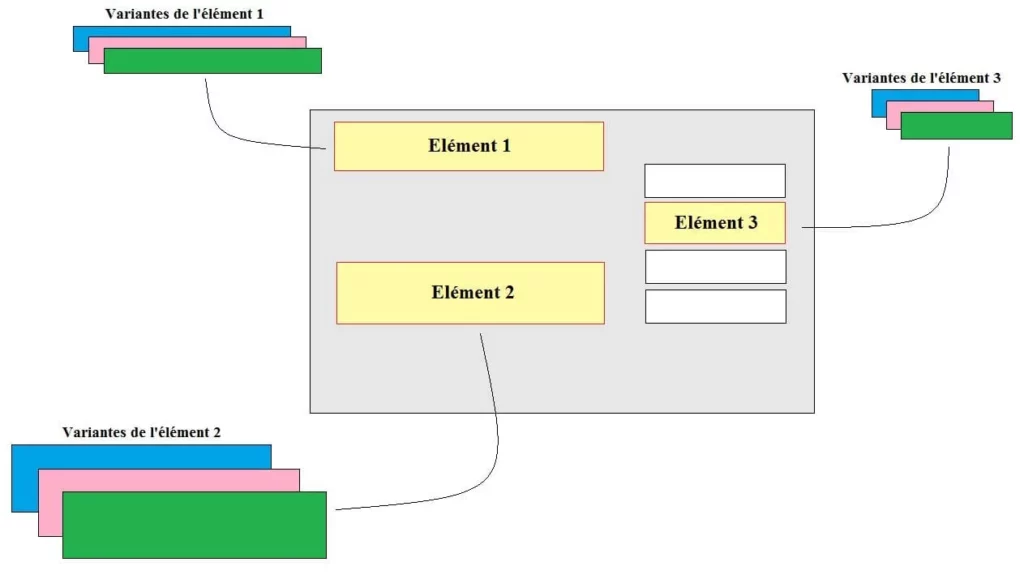
Chaque élément a un impact spécifique, ce qui vous permettra de faire ressortir le meilleur de votre site. Ici voici comment :
- Utiliser l’A/B testing pour déterminer les meilleurs agencements / mises en pages
- Utiliser les tests multivariés pour peaufiner les mises en pages et s’assurer que tous les éléments interagissent bien ensemble
Vous avez besoin d’un grand trafic sur les pages que vous voulez tester même pour le test multivarié ! Si vous avez suffisamment de trafic, vous devriez utiliser les deux types de tests.
De nombreuses agences priorisent le test A/B car elles testent généralement plus de changements significatifs (avec de plus gros impacts potentiels), et car ils sont plus simples à exécuter.
Les algorithmes bandits sont des tests A/B/n qui se mettent à jour en temps réel en fonction des performances de chaque variante.
Un algorithme bandit commence par l’envoi de trafic sur deux pages (ou plus) : l’original et une ou des variantes. Ensuite, pour gagner plus souvent à la machine à sous, l’algorithme s’actualise en fonction la variante « gagnante ». Il peut éventuellement exploiter entièrement la meilleure option :
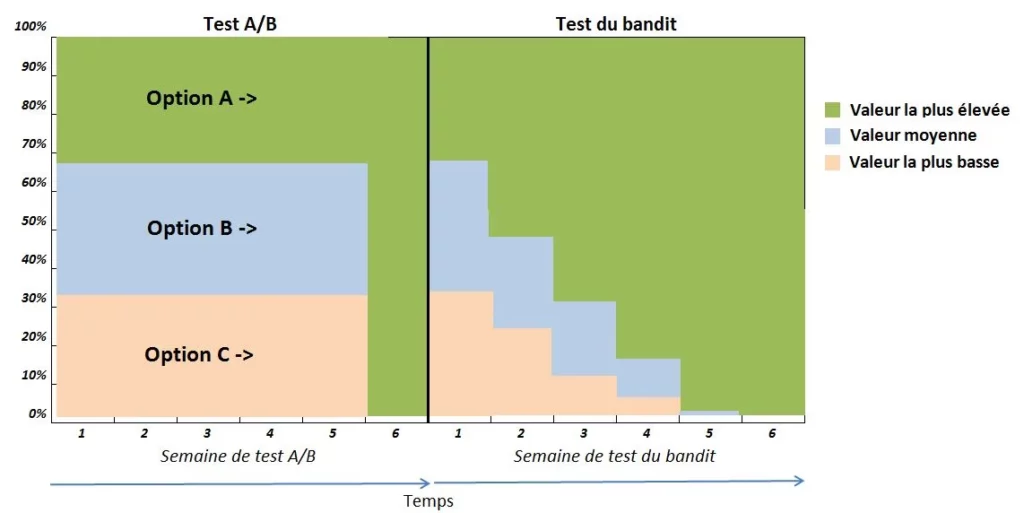
Un des avantages du test du bandit est qu’il atténue le “regret”, qui est la possibilité de perte de conversion, pendant qu’il teste une variation potentielle pire que le témoin.
Les tests du bandit et A/B/n ont chacun une raison d’exister. En général, le test du bandit est super pour :
- Les headers et les campagnes à court-terme ;
- L’automatisation;
- Le ciblage ;
- L’optimisation avec attribution.
Peu importe le type de tests que vous lancez, il est important d’avoir un process qui améliore vos chances de réussite, c’est-à-dire plus de conversions.
Comment améliorer les résultats de vos A/B tests ?
Ignorez les posts de blogs qui vous disent “99 choses que vous pouvez tester maintenant avec le test A/B ». Ce sont des pertes de temps et de trafic. Un process vous rapportera plus d’argent.
Quelques 74% des optimiseurs avec une approche de conversion structurée déclarent aussi améliorer leurs ventes. Ceux sans approche structurée restent dans ce que Craig Sullivan appelle la « pensée de désillusion » (sauf si leurs résultats sont des tas de faux positifs, ce que nous montrerons plus tard).
Pour simplifier un process gagnant, la structure ressemble à quelque chose comme cela:
- Recherche
- Priorisation
- Expérimentation
- Analyse, étude et répétition
Recherche : obtention de perspectives axées sur les données
Pour commencer l’optimisation, vous avez besoin de connaitre ce que vos utilisateurs font et pourquoi.
Avant de penser à l’optimisation et aux tests, cependant, solidifiez votre stratégie de haut niveau et avancez dans cette direction. Donc, pensez dans cet ordre :
- Définissez vos objectifs commerciaux
- Définissez les objectifs de votre site
- Définissez vos KPI
- Définissez vos métriques cibles

Une fois que vous savez où vous voulez aller, vous pouvez collecter les données nécessaires pour vous y rendre. Ci-dessous la synthèse du process utilisé :
- Analyse heuristique
- Analyse technique
- Analyse web analytic
- Analyse de suivi de la souris
- Enquête qualitatives
- Test utilisateurs
L’analyse heuristique est quelque chose qui se rapproche de nos “best practices”. Même après des années d’expérience, nous ne pouvons toujours pas dire comment cela fonctionne exactement. Mais nous pouvons identifier des champs d’opportunités. Comme Craig Sullivan le dit :

L’humilité est cruciale. Cela aide aussi à avoir une structure. Lors d’une analyse heuristique, nous évaluons chaque page sur ce qui suit :
- La pertinence ;
- La clarté ;
- La valeur ;
- Les conflits ;
- La distraction.
L’analyse technique est souvent négligée mais les bugs, s’il y en a aux alentours, sont des tueurs de conversion. Vous pourriez penser que votre site fonctionne parfaitement en termes d’expérience utilisateur et fonctionnalité. Mais fonctionne-t-il aussi bien avec tous les navigateurs et appareils ? Probablement pas.
Il s’agit d’une des tâches des plus faciles et hautement profitable. Donc commençons par :
- Mener des tests multi-navigateurs et multi-appareils
- Faire une analyse de page speed
L’analyse du Web analyticc est la suivante. D’abord, la première chose est de vous assurer que tout fonctionne. (Vous serez surpris par le nombre d’outil d’analytiques qui sont erronés).
Ci-dessous quelques liens utiles :
- Comment installer Google Analytics
- Comment définir vos objectifs, les segments et vos évènements dans Google Analytics
Le suivant est l’analyse du mouse-tracking ou suivi de la souris, qui inclue les cartes thermiques, les cartes de défilement, les cartes de clics, les formulaires, et les replays de sessions d’utilisateurs. Ne portez pas trop d’attention à l’esthétique des cartes de clics. Soyez sûr que vous façonnez vos plus larges objectifs avec cette étape.
La recherche qualitative vous dit le pourquoi de l’analyse quantitative. Beaucoup de gens pensent que l’analyse qualitative est plus douce, plus simple que l’analyse quantitative, mais elle devrait être aussi rigoureuse et pouvoir fournir des perspectives aussi importantes que celles de l’analytic.
Pour de la recherche qualitativve, utilisez des choses comme :
- Enquêtes en ligne;
- Enquêtes clients;
- Interviews de clients et groupes cibles.
Enfin, il y a le test utilisateur. Le postulat est simple : observez quelles personnes utilisent et interagissent actuellement avec votre site pendant qu’ils racontent leurs pensées à voix haute. Faîtes attention à ce qu’ils disent et à ce qu’ils expérimentent.
Après une recherche de conversion minutieuse, vous obtiendrez beaucoup de données. La prochaine étape est de prioriser ces données pour les tester.
Comment prioriser les hypothèses de l’A/B testing ?
Il existe de nombreuses structures pour prioriser vos tests A/B, et vous pourriez même innover avec votre propre formule. Ci-dessous un moyen de prioriser votre travail.
Une fois que vous aurez traversé ces six étapes, vous trouverez des problèmes, quelques uns sévères, d’autres mineurs. Attribuez à chaque découverte l’un des cinq points suivants :
- Test. C’est là où vous placerez les choses à tester
- Outil. Cela peut supposer une réparation, un ajout, une amélioration de tag / d’évènement
- Emission d’une hypothèse. C’est là où vous avez trouvé une page, un widget, un process qui ne marche pas bien mais dont la résolution du problème n’est pas très claire.
- A faire. C’est le point dans lequel il n’y a pas à se tirer les cheveux. Il faut simplement faire les choses.
- A rechercher. Si un élément est placé ici, il faudra vous poser plus de questions / creuser plus loin.
Notez chaque problème avec un nombre d’étoiles compris entre 1 (mineur) et 5 (critique). Deux critères sont plus importants que les autres pour la notation :
- Facilité de mise en œuvre (temps, difficulté, risque). Parfois, les données vous disent de créer une fonctionnalité qui prendrait des mois à être développée. Ne commencez pas par là.
- Opportunité. La notation des problèmes est subjectivement basée sur le niveau de changement que cela pourrait engendrer.
Créez un tableur avec toutes les données. Vous aurez une cartographie des tests à prioriser.
Ci-dessous le modèle de priorisation PXL proposé par ConversionXL. Il est basé sur la nécessité de pouvoir mettre les données sous forme de tableau.
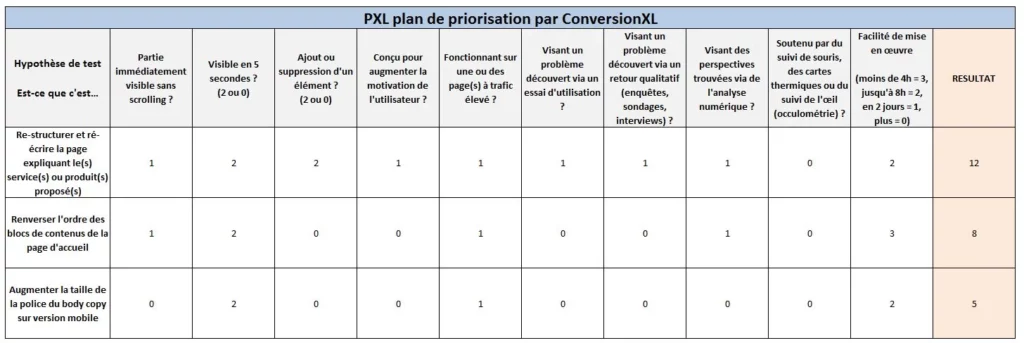
Enregistrez votre propre modèle de tableur ici. Cliquez simplement sur Fichier >> Créer une copie pour vous l’approprier.
Au lieu de deviner quel devrait être l’impact, ce framework vous propose de répondre à une série de questions :
- Le changement est-il immédiatement visible sans avoir besoin de faire défiler le contenu ? Plus de gens remarquent des changements visibles sans scrolling. Donc ces changements ont plus de chances d’avoir de l’impact.
- Le changement peut-il être remarqué en moins de 5s ? Montrez à un groupe de personne le témoin et les variantes. Peuvent-ils vous donner la différence au bout de 5s ? Si non, l’impact est probablement faible.
- Est-ce que cela ajoute ou enlève quelque chose ? De gros changements comme la suppression de distractions ou l’ajout d’informations clés ont tendance à avoir de l’impact.
- Le test est-il exécuté sur des pages à fort trafic ? Une amélioration sur une page à haut trafic génère de plus gros retours.
De nombreuses variables potentielles de tests nécessitent de prioriser vos hypothèses. Vous poser ces 4 questions vous aidera à prioriser vos expérimentation en se basant sur les données, et non vos opinions :
- Est-ce que cela concerne un problème découvert lors d’un test utilisateur ?
- Est-ce que cela concerne un problème découvert lors d’un retour qualitatif (enquêtes, sondages, interviews) ?
- Est-ce une hypothèse supportée par du suivi de souris, des cartes thermiques ou du suivi visuel ?
- Est-ce que cela concerne des perspectives mises en évidence par analyse numérique ?
Il est également ajouté dans ce tableur la facilité de mise en œuvre avec entre parenthèse une réponse en fonction du temps estimé. Idéalement, un développeur de test fait partie des discussions de priorisation.
Notation PXL
Le modèle PXL contient deux échelles. Libre à vous de choisir l’une ou l’autre. Donc, pour plus de variables (sauf si noté autrement) vous choisirez soit 0 soit 1.
Ce modèle permet aussi de donner un niveau d’importance aux variables. A quel point le changement est-il visible ? si quelque chose est ajouté / supprimé ? si c’est facile à mettre en œuvre ? Pour ces variables, il est spécifiquement indiqué combien de choses changent. Par exemple, pour la visibilité de la variable changée, vous pouvez noter soit 2 soit 0.
Personnalisation
Ce modèle a été construit avec la conviction que vous pouvez et devriez personnaliser vos variables en fonction de ce qui compte pour votre business.
Par exemple, peut-être que vous travaillez avec une marque ou une expérience utilisateur en tant qu’équipe. Vos hypothèses doivent donc être en accord avec les lignes directrices de la marque. Ajoutez-le comme une variable.
Peut-être êtes-vous une start-up avec un moteur d’acquisition alimenté par la SEO. Peut-être que vos financements dépendent d’un flot de clients. Ajoutez une catégorie comme « n’interfère pas avec la SEO », ce qui pourrait modifier certains gros titres ou copy tests.
Toutes les organisations opèrent sous certains principes. Personnaliser le template peut avoir de l’importance pour elles et peaufiner votre programme d’optimisation.
Quelle que soit la structure que vous utilisez, rendez-là systématique et compréhensible par tous les membres de votre équipe et parties prenantes.
Combien de temps faire durer les A/B tests ?
Règle n°1 : ne pas arrêter un test parce qu’il a atteint de l’importance statistique. C’est probablement la plus commune des erreurs commises par les optimiseurs débutants portés par de bonnes intentions.
Si vous interrompez le test quand il prend de l’importance, vous trouverez que la plupart des modifications ne se traduisent pas par une augmentation de revenus (c’est l’objectif, après tout).
Considérez ceci : Lorsque 1 000 tests A/A (deux pages identiques) sont lancés :
- 771 expérimentations sur 1 000 atteignent 90% de signification à un moment donné
- 531 expérimentations sur 1 000 atteignent 95% de signification à un moment donné
L’arrêt des tests avant obtention d’un résultat statistiquement significatif peut conduire à des faux positifs et à des menaces externes, comme la saisonnalité.
Prédéterminer la taille de l’échantillon et exécuter le test pendant plusieurs semaines, généralement au moins pendant 2 cycles économiques.
Comment prédéterminer la taille de l’échantillon à tester ? Il y a un tas d’outils super pour ça. Ci-dessous voici comment vous calculeriez la taille de l’échantillon avec l’outil d’Evan Miller :
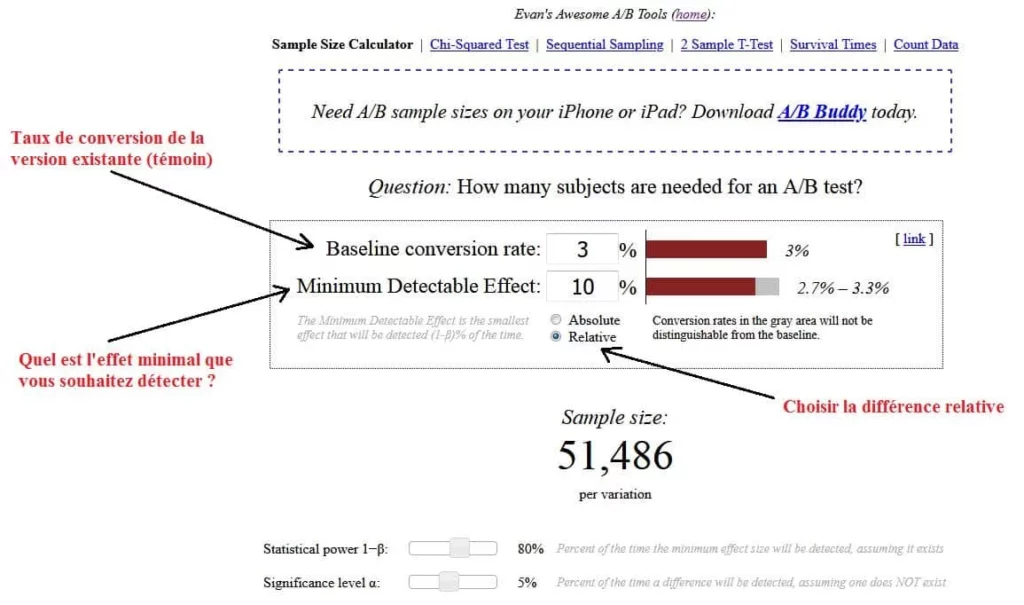
Dans cet exemple, nous avons indiqué à l’outil que nous avions un taux de conversion de la version témoin de 3% et que nous voulions détecter un taux minimal de 10%. L’outil nous dit qu’il faut 51 486 visiteurs par variante avant de pouvoir observer des niveaux statistiquement significatifs.
En plus de ces niveaux, il y a ce qu’on appelle la puissance statistique. Elle essaye d’éviter les erreurs de Type II (faux négatifs). En d’autres termes, elle augmente la chance que vous détectiez un effet s’il en est vraiment un.
Pour des raisons pratiques, sachez qu’une puissance de 80% est le standard pour les outils d’ab testing. Pour atteindre un tel niveau, il vous faut soit une grande taille d’échantillon, un effet important ou une durée de test plus longue.
Il n’y a pas de nombres magiques
Beaucoup de posts de blogs font la promotion de nombres magiques comme « 100 conversions » ou « 1 000 visiteurs » comme point d’arrêt des tests. Les maths ne sont pas de la magie, et ce dont nous sommes en train de parler est légèrement plus complexe que de l’heuristique simpliste comme ces nombres. Andrew Anderson de Malwarebytes l’a bien dit :
Cent conversions sont possibles dans des cas isolés et avec un delta sur le comportement incroyablement élevé, mais seulement si d'autres conditions nécessaires comme le comportement au fil du temps, l'uniformité et une distribution normale sont présents. Il y a déjà une grande chance d'avoir une erreur de Type I, un faux positif. »
Nous voulons un échantillon représentatif. Comment obtenir cela ? Test pour 2 cycles économiques atténuer les facteurs externes :
- Jour de la semaine. Votre trafic journalier peut varier beaucoup.
- Sources du trafic. Sauf si vous voulez personnaliser l’expérience pour une source dédiée.
- Programme de publication de posts et de newsletter.
- Visiteurs revenant. Des gens pourraient visiter votre site, penser à acheter, puis revenir 10 jours après pour passer vraiment à l’achat.
- Évènements externes. Un paiement à mi-mois pourrait affecter l’achat, par exemple.
Soyez vigilant avec les petites tailles d’échantillons. Internet est riche en use case avec des maths de bas étage. La plupart des études (si elles sont déjà en grand nombre) révéleraient que les éditeurs ont jugé des tests de variations sur 100 visiteurs ou un lift de 12 à 22 conversions.
Une fois que tout est installé correctement, évitez de jeter un oeil (ou laisser votre supérieur le faire) sur les résultats du test avant la fin du test. Cela peut résulter en l’appel d’un résultat trop tôt dû à l’identification d’une tendance (impossible). Ce que vous trouverez c’est que beaucoup de résultats de tests régressent vers la moyenne.
Régression vers la moyenne
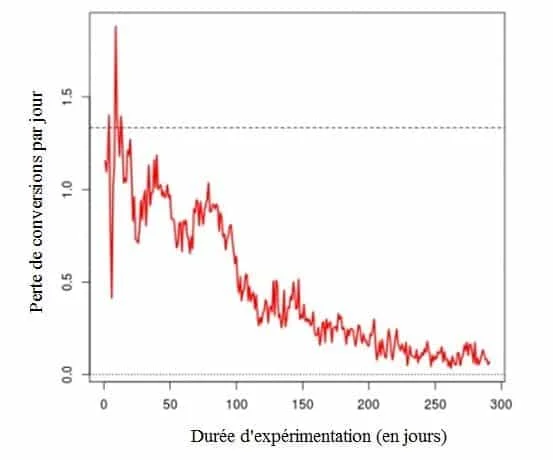
Souvent, vous verrez des résultats variant largement lors des premiers jours de tests. Sans surprise, ils ont tendance à converger quand le test se poursuit pendant les semaines suivantes. Ci-dessous un exemple pour un site d’e-commerce :
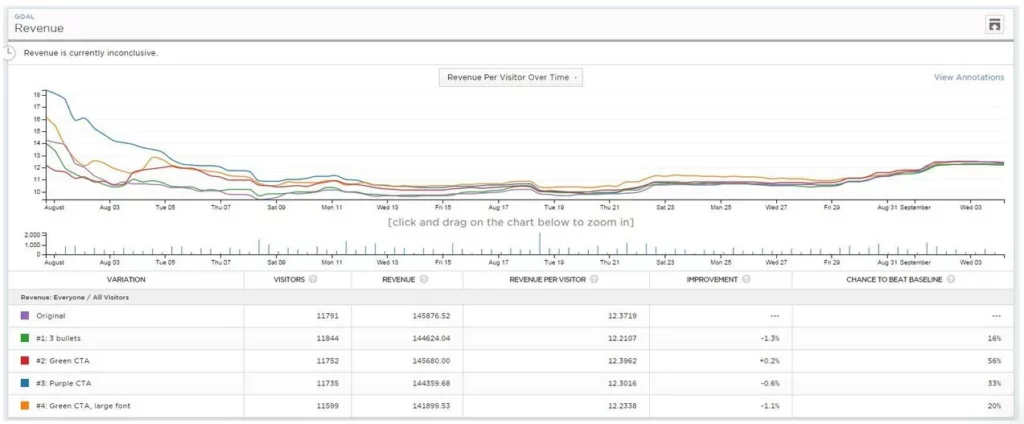
- Les deux premiers jours : la courbe bleue (variante n°3) est largement gagnante – environ 16 dollars par visiteur contre 12,50 dollars par visiteur pour le témoin. De nombreuses personnes voudraient (à tort) arrêter le test ici.
- Après 7 jours : la courbe bleue continue d’être gagnante et la différence relative est importante.
- Après 14 jours : la courbe orange (variante n°4) est gagnante !
- Après 21 jours : la courbe orange continue à être gagnante !
- A la fin du test : pas de différence.
Si vous aviez communiqué sur les résultats à moins de 4 semaines, vous auriez pu retenir une conclusion erronée.
C’est un problème connu : l’effet de nouveauté. La nouveauté des changements (c’est-à-dire le plus gros bouton bleu) attire plus d’attention sur la variante. Après quelques temps, le lift disparait car le changement ne reste pas longtemps nouveau.
Peut-on lancer plusieurs A/B tests en simultané ?
Vous voulez accélérer votre programme d’essais et exécuter plusieurs tests – avec une cadence de tests élevée. Mais pouvez-vous lancer plus qu’un A/B test à la fois ? Est-ce que cela augmentera votre croissance potentielle ou polluera vos données ?
Certains experts disent que vous ne devriez pas faire de tests multiples simultanément. D’autres disent que c’est bien. Dans la plupart des cas, vous serez content de pouvoir lancer en simultané plusieurs tests ; des interactions importantes sont peu probables.
A moins que vous soyez en train de tester des choses vraiment importantes (c’est-à-dire quelque chose qui impacte votre business model, l’avenir de votre société), le bénéfice de tester du volume aura probablement plus d’importance que les interférences dans vos données et les faux positifs occasionnels.
S’il y a un risque élevé d’interaction entre tests multiples, réduisez le nombre de tests en simultané et/ou laissez tourner le test plus longtemps pour une plus grande précision.
Comment lancer des tests A/B ?
Une fois que vous avez une liste priorisée d’idées à tester, il est temps de formaliser une hypothèse et de lancer l’expérimentation. Une hypothèse définit pourquoi vous croyez qu’un problème a lieu. De plus, une bonne hypothèse :
- est testable. Elle est mesurable, donc elle peut être testée.
- résout un problème de conversion. Un test de division résout des problèmes de conversion.
- fournit des perspectives de marché. Avec une hypothèse bien articulée, les résultats de votre test de division vous donne des informations sur vos clients, peut importe que le test soit « gagnant » ou « perdant ».
Craig Sullivan a un kit d’hypothèse pour simplifier le process :
- Parce que nous l’avons vu (données, feedback)
- Nous nous attendons à ce que ce (changement) engendre cet (impact)
- Nous mesurerons cela en utilisant (des données métriques)
Et le plus avancé :
- Parce que nous l’avons vu (données qualitatives et quantitatives)
- Nous nous attendons à ce que ce (changement) pour (ce type de personnes) engendre ce(s) (impact(s))
- Nous nous attendons à voir (ces changements de données métriques) sur une période de (X cycles économiques)
A/B testing Partie technique
Voici la partie la plus fun : vous pouvez enfin penser à la sélection de l’outil.
Bien que ce soit la première chose à laquelle les gens pensent, ce n’est pas le plus important. La stratégie et les connaissances en statistique viennent en premier.
il y a quelques différences à garder en tête. Un des principaux classements des outils consistent à savoir si l’outil effectue le test du côté du serveur ou du côté du client.
Les outils côté serveur apportent du code sur le niveau serveur. Ils envoient une version randomisée de la page à la visionneuse sans modification sur le navigateur du visiteur. Les outils côté client envoient la même page, mais le JavaScript sur le navigateur du client arrange l’apparence de l’original et de la variante.
Les outils de test côté client incluent Optimizely, VWO, et Adobe Target. Conductrics a la capacité de faire les deux, et SiteSpect utilise une méthode proxy côté serveur.
Qu’est-ce que tout cela signifie pour vous ? Si vous aimeriez gagner du temps en amont, ou si votre équipe est petite ou manque de développement de ressources, les outils côté client peuvent être plus adaptés et s’exécuter plus rapidement. Les outils côté serveur nécessitent des développements de ressources mais peuvent souvent être plus fiables.
Bien que le paramétrage des tests soit légèrement différent en fonction de l’outil utilisé, il est souvent aussi simple que de s’inscrire à votre outil favori et suivre ses instructions, comme mettre un snippet JavaScript sur votre site.
Au-delà de cela, vous avez besoin d’installer Goals (pour savoir quand une conversion a été faite). Votre outil de test réalisera un suivi à chaque fois qu’une variante convertit des visiteurs en clients.
Une page de remerciement peut servir d’objectif dans Google Analytics.
Les compétences qui se montrent utiles lors du paramétrage d’A/B tests sont HTML, CSS et JavaScript/JQuery, tout comme des compétences en design et en copywriting pour réaliser des variantes. Certains outils permettent l’utilisation d’éditeur visuel.
Comment analyser les résultats de tests A/B ?
Bon, vous avez fait votre recherche, paramétré votre test correctement et le test est finalement réalisé. Maintenant, place à l’analyse. Ce n’est pas aussi simple qu’un aperçu sur un graphe depuis un outil de test.
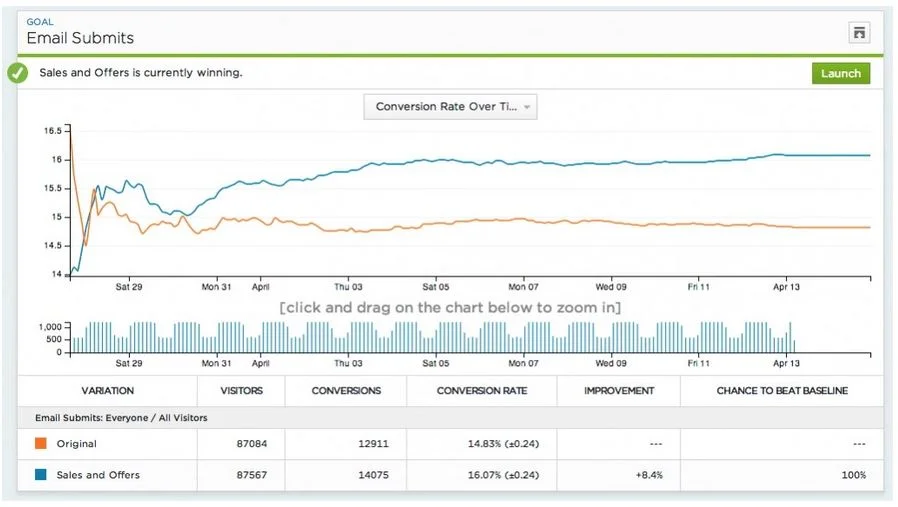
Une chose que vous devriez toujours faire est d’analyser les résultats du test sur Google Analytics. Cela n’améliore pas juste vos capacités d’analyse, cela vous permet aussi d’avoir plus confiance en vos données et en vos prises de décision.
Votre outil de test pourrait enregistrer des données de façon incorrecte. Si vous n’avez pas d’autre source pour vos données de test, vous ne pouvez jamais être sûr que vous pouvez avoir confiance en ces données. Créez des sources multiples de données.
Que se passe-t-il s’il n’y a pas de différence entre les variantes ? Ne passez pas à autre chose trop vite. D’abord, rendez-vous compte de deux choses :
1.Votre hypothèse était peut-être la bonne mais l’exécution était mauvaise.
Supposons que votre recherche qualitative dit que l’aspect sécurité est un problème. Par combien de moyens pouvez-vous renforcer la perception de sécurité ? C’est illimité.
2. Même s’il n’y avait pas de différence dans l’ensemble, la variante pourrait battre le témoin sur un segment ou deux.
Si vous avez un lift pour les visiteurs qui reviennent et les visiteurs sur appareils mobiles – mais une baisse pour les nouveaux visiteurs et les utilisateurs sur pc – ces segments pourraient s’annuler l’un et l’autre, faisant comme s’il n’y avait aucune différence. Analyser votre test sur des segments clés pour rechercher cette possibilité.
Segmentation de données pour tests A/B
La clé de l’apprentissage de l’A/B testing est la segmentation. Bien que B pourrait perdre face à A dans les résultats généraux, B pourrait battre A sur certains segments (naturel, Facebook, mobile,etc.).
Il y a une tonne de segments qui peuvent être analysés. Optimizely liste les possibilités suivantes :
- Type de navigateur ;
- Type de source ;
- Mobile vs ordinateur, or par appareil ;
- Visiteurs inscrits ou non inscrits ;
- Campagnes PPC/SEM ;
- Régions géographiques (ville, Etat / province, pays) ;
- Nouveaux visiteurs ou visiteurs ayant déjà consulté la page ;
- Nouvel achat ou achats répétés ;
- Utilisateurs réguliers vs utilisateurs occasionnels ;
- Hommes vs femmes ;
- Tranche d’âge ;
- Nouveaux leads vs leads déjà acquis ;
- Type de plan ou niveaux de programme fidélité ;
- Anciens, actuels et potentiels abonnés ;
- Rôles (si votre site a, par exemple, à la fois un rôle d’acheteur et de vendeur).
Au strict minimum – en admettant que vous avez une taille d’échantillon adéquate – penchez-vous sur ces segments :
- Pc vs tablette / mobile ;
- Nouveaux visiteurs ou visiteurs ayant déjà consulté la page ;
- Trafic qui atterrit sur la page vs trafic depuis des liens internes.
Assurez-vous que vous avez une taille d’échantillon suffisante dans le segment. Calculez-le à l’avance, et soyez sur vos gardes s’il y a moins de 250-350 conversions par variante dans un segment donné.
Si votre traitement fonctionne bien pour un segment spécifique, il est l’heure de considérer une approche personnalisée pour ces utilisateurs-là.
Comment archiver les tests A/B précédents ?
Les tests A/B ne portent pas juste sur des lifts, des victoires, des défaites, et des tests aléatoires. Comme Matt Gershoff l’a dit, l’optimisation concerne « le rassemblement d’informations pour façonner des décisions », et les connaissances obtenues via des A/B tests statistiquement valides contribue à servir de plus grands objectifs de croissance et d’optimisation.
Les organisations intelligentes archivent leurs résultats de tests et planifient leur approche avec des tests systématiques. Une approche structurée d’optimisation conduit à une plus grande croissance !
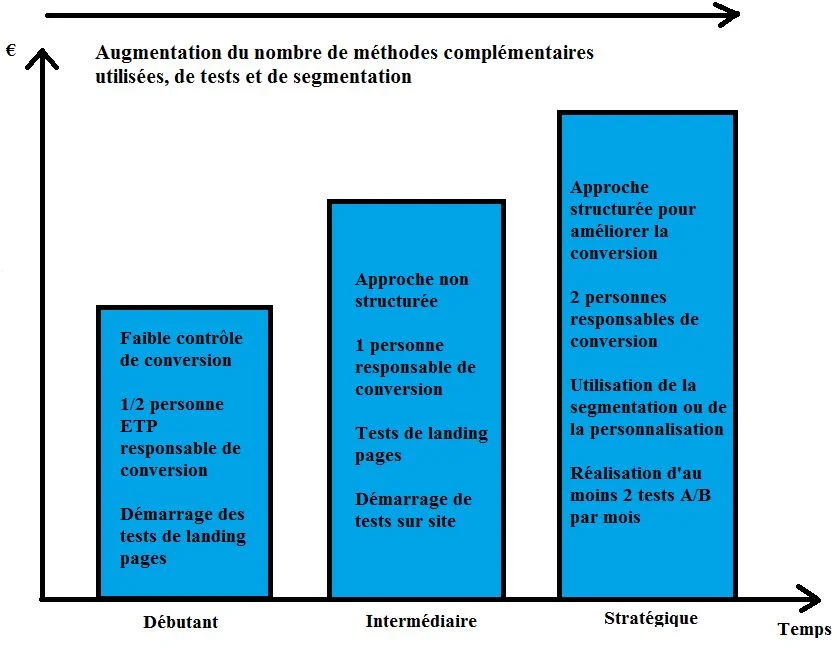
Il n’y a pas un seuil meilleur moyen de structurer votre management de connaissance. Certaines entreprises utilisent des outils sophistiquées réalisés en interne; d’autres utilisent des outils d’une tierce partie; et d’autres encore utilisent Excel et Trello.
Ci-dessous trois outils créés spécifiquement pour le management de projet d’optimisation de conversion :
Il est important de communiquer à travers les départements et avec la direction. Souvent, les résultats des A/B tests ne sont pas intuitifs pour une personne non-initiée. La visualisation aide.
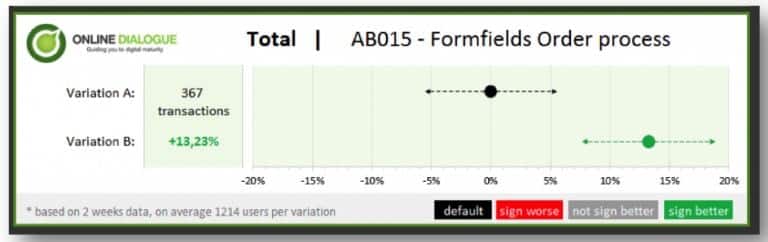
Statistiques d’A/B testing
Des connaissances statistiques sont utiles pour l’analyse des résultats d’A/B test. Nous en avons déjà parlé plus haut, mais il y a encore bien plus à dire.
Il y a 3 termes que vous devriez connaitre avant que nous ne passions au sujet sérieux des statistiques de test A/B :
- Moyenne. Nous ne sommes pas en train de mesurer tous les taux de conversions, seulement celui d’un échantillon. La moyenne est représentative du tout.
- Ecart. Quelle est la variabilité naturelle d’une population ? Cela affecte nos résultats et la façon dont on les utilise.
- Echantillonnage. Nous ne pouvons pas mesurer le taux de conversion réel, donc nous sélectionnons un échantillon qui est (heureusement) représentatif.
Qu’est-ce qu’une valeur-p ?
De nombreuses personnes utilisent le terme « statistiquement significatif » à mauvais escient. La signification statistique en elle-même n’est pas une règle arrêtée, donc qu’est-ce que c’est et pourquoi est-ce important ?
Pour commencer, parlons des valeurs-p, qui sont aussi très mal comprises. Comme FiveThirtyEight l’a récemment signalé, même les scientifiques ne peuvent pas facilement expliquer les valeurs-p.
Une valeur-p représente la probabilité de faire un faux positif, ou de rejeter l’hypothèse nulle si elle est vraie. Une valeur-p ne donne pas la probabilité que B soit meilleur que A.
De façon similaire, elle ne donne pas la probabilité que nous fassions une erreur en sélectionnant B plutôt que A. Ce sont des idées fausses communes.
La valeur-p est la probabilité d’avoir le résultat actuel ou un résultat plus extrême étant donné que l’hypothèse nulle est vraie. Ou « A quel point ce résultat est-il surprenant ? ».
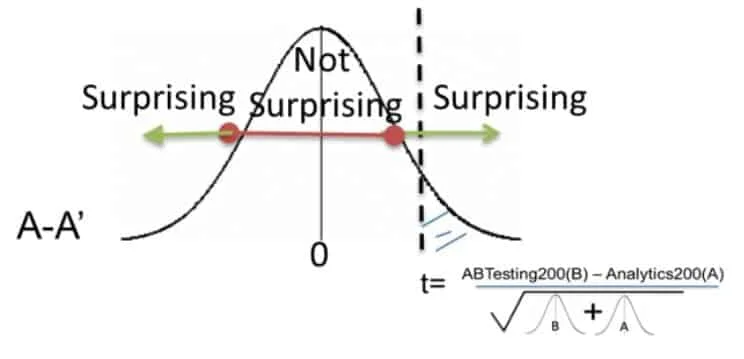
Pour résumer, la signification statistique (ou résultat statistiquement significatif) est atteinte quand une valeur-p est plus faible que le niveau de signification (qui est habituellement fixé à 0.05).
La signification au regard du test de l’hypothèse statistique s’applique aussi quand un problème « unilatéral vs bilatéral »
A/B Tests unilatéraux vs bilatéraux
Des tests unilatéraux permettent un effet dans une direction. Des tests bilatéraux recherchent un effet bidirectionnel – positif ou négatif.
Intervalle de confiance et marge d’erreur
Votre taux de conversion ne dit absolument pas X%. Il dit quelque chose comme X% (+/- Y). Ce second nombre est l’intervalle de confiance, et il est très important pour comprendre les résultats des tests.
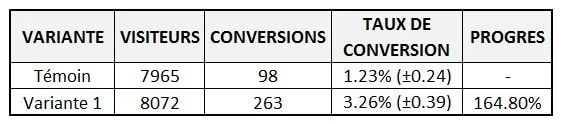
Dans le test A/B, nous utilisons des intervalles de confiance pour réduire le risque d’erreur d’échantillonnage. En ce sens, nous manageons le risque associé en implémentant une nouvelle variante.
Donc si votre outil dit quelque chose comme « nous sommes à 95% sûr que le taux de conversion est de X% +/-Y% », alors vous avez besoin de savoir que le +/-Y% est la marge d’erreur.
Le niveau de confiance que vous pouvez avoir en vos résultats dépend largement de la valeur de cette marge d’erreur. Si les 2 plages de conversion se recoupent, vous avez besoin de continuer le test pour obtenir un résultat valide.
Menace externe de validité
Il y a un défi quand on lance des tests A/B : les données ne sont pas stationnaires.
Une série chronologique stationnaire est une série dont les propriétés statistiques (moyenne, écart, autocorrélation, etc.) sont constantes en fonction du temps. Pour diverses raisons, les données des sites ne sont pas stationnaires, ce qui signifie que nous ne pouvons pas faire les mêmes hypothèses que pour des données stationnaires. Ci-dessous quelques raisons pour lesquelles les données pourraient fluctuer :
- Saison ;
- Jour de la semaine ;
- Vacances ;
- Mentions positives ou négatives dans la presse ;
- Autres campagnes marketing ;
- PPC/SEM ;
- SEO;
- Bouche à oreille.
Statistiques bayésiennes ou fréquentistes
Le test A/B bayésien ou fréquentiste est un autre sujet chaud. De nombreux outils populaires ont reconstruit leurs moteurs statistiques pour fonctionner suivant une méthodologie bayésienne.
Ici la différence (vraiment très simplifiée) : D’un point de vue bayésien, une probabilité est assignée à une hypothèse. D’un point de vue fréquentiste, une hypothèse est testée sans être assignée à une probabilité.
Rob Balon, qui a réalisé un doctorat en recherches statistiques et marché, raconte le débat sous un angle ésotérique. Il dit que « la plupart des analystes à l’extérieur de la tour d’ivoire ne se soucient pas beaucoup, voire pas du tout, du bayésien vs fréquentiste ».
Ne vous méprenez pas, il y a des intérêts commerciaux pratiques pour chaque méthodologie. Mais si vous êtes novice dans le test A/B, il y a des choses bien plus importantes pour vous.
Outils et ressources pour l’A/B testing
Tout au long de ce qui suit, vous trouverez des tas de liens vers des ressources externes : articles, outils, livres, etc. Pour rendre tout ça plus commode pour vous, ci-dessous les plus importants (divisés en catégories).
Outils de test A/B
Il y a beaucoup d’outils pour de l’expérimentation en ligne. Ci-dessous une liste de 53 outils d’optimisation de conversion, tous vérifiés par des experts. Certains des outils de tests A/B les plus populaires incluent :
- Optimizely ;
- VWO ;
- Adobe Target ;
- Maximyser ;
- Conductrics.
Calculateurs pour test A/B
- Calculateur pour test A/B
- Calculateur de signification pour test de division A/B par VWO ;
- Calculateur de durée de test de division et de test multivarié par VWO;
- Calculateur de taille d’échantillon d’Evan Miller.
Conclusion A/B Testing
Le test A/B est une ressource inestimable pour toute personne prenant des décisions dans un environnement en ligne. Avec un peu de connaissance et beaucoup d’assiduité, vous pouvez réduire de nombreux risques auxquels la plupart des optimiseurs débutants font face.
Si vous approfondissez vraiment les informations données ici, vous serez en avance sur 90% des gens qui lancent des tests. Si vous croyez en la puissance de l’A/B testing pour une croissance de revenus continue, votre place est ici.
Les connaissances sont un facteur limitant que seule l’expérience et l’apprentissage itératif peuvent transcender. Donc c’est parti : à vous de tester !
Nos dernières success story en analytics
Blast Club
Blast.club, dirigé par Anthony Bourbon, est une plateforme qui permet d'investir dans des startups via des adhésions qui donnent accès à des opportunités exclusive.
Majelan
Majelan, fondée par Mathieu Gallet, est une plateforme de podcasts offrant des contenus audio variés et personnalisés, allant des fictions aux masterclasses, avec une expérience sans publicité.
Cybertek & Grosbill
Le groupe Cybertek a racheté Grosbill en 2018, relançant la marque spécialisée dans le matériel informatique. Cybertek a renforcé son réseau de vente en ligne et en magasins physiques en fusionnant les deux enseignes
Weglot
Weglot est une solution simple pour traduire un site web en plusieurs langues en quelques minutes, sans coder. Elle s'intègre avec des plateformes comme WordPress et Shopify, tout en optimisant le SEO multilingue.
Altaroc
Altaroc.pe permet aux investisseurs privés d'accéder aux meilleurs fonds de Private Equity avec des opportunités diversifiées et simplifiées, autrefois réservées aux grandes institutions.
Teamviewer
TeamViewer est un logiciel de contrôle à distance pratique pour le dépannage et le télétravail, gratuit pour un usage personnel. L’entreprise allemande qui le développe est valorisée à environ 2,4 milliards d’euros, confirmant son statut de leader mondial en télémaintenance.
Chaque semaine, recevez les meilleurs articles growth résumés et découvrez un outil unique pour booster votre business. Profitez aussi d’outils gratuits et de webinars exclusifs.