Introduction au Web Scraping avec Puppeteer
Dans cet article, je vous invite à découvrir le Web Scraping avec Puppeteer.
Il y a quelques jours, j’ai visionné une vidéo sur DevTips dans laquelle ils essayaient d’utiliser Puppeteer. Je ne l’ai jamais utilisé mais j’ai pensé que ça avait l’air vraiment cool. Du coup, j’ai demandé une version d’essai. Je partage avec vous ce que j’ai appris ici.
SOMMAIRE
- Pré-requis
- Qu’est-ce que Puppeteer ?
- Pourquoi utiliser un navigateur headless ?
- Un peu de code
- Scraping plus avancé
- Références et liens
Pré-requis
Ce tutoriel est adapté aux débutants. Aucune connaissance particulière en code n’est requise. Si vous suivez le projet jusqu’au bout, plus de pré-requis seront listés sous la section de code.
Tous les codes seront disponibles sur GitHub (lien ici).
Vous trouverez ici un lien vers l’exemple proposé par CodeDraken.
Qu’est-ce que Puppeteer ?
Avant de se plonger dans du code, il est important de comprendre à quoi correspond la technologie que nous allons utiliser et pourquoi elle existe.
Un navigateur headless
Puppeteer va de pair avec Chromium et fonctionne par défaut « headless ». Mais qu’est-ce qu’un navigateur headless (en anglais : a headless browser) ? C’est un navigateur pour « machines ». Il n’a pas d’interface utilisateur et permet à un programme — souvent appelé un « scraper » ou un « crawler » — de lire ou d’interagir avec lui.
Une API
Les navigateurs headless sont super et complets, mais ils peuvent être pénibles à utiliser parfois. Puppeteer, néanmoins, fournit une belle API (interface de programmation d’application ou « Application Programming Interface » en anglais) avec toute une panoplie de fonctions pour interagir avec lui.
Avec +12 ans d’experiences en marketing et en growth. deux.io a accompagné plus de 500 entreprises dans leur croissances digitales. Nous appliquons des méthodes avancés en growth pour cibler engager, et convertir vos prospects en clients.
Pourquoi utiliser un navigateur headless ?
Il y a tant de choses à faire avec Puppeteer et le web scraping en général !
- Faire des tests automatiques sur des pages web existantes
- Générer des PDF
- Faire des impressions écrans
- Obtenir des données depuis des sites et les conserver
- Automatiser des tâches ennuyantes
Un peu de code !
C’est parti !
Pré-requis
Si vous suivez l’ensemble de cet article, vous aurez besoin d’installer NodeJS, d’une connaissance basique des lignes de commande, de JavaScript et de connaitre un peu le DOM (Document Object Model).
Installation
- Créez un dossier (nommez-le comme vous voulez, sans espace si possible)
- Sélectionnez le dossier dans votre terminal (cd repertoire_vers_votre_dossier)
- Dans votre terminal, lancez
npm init -yCeci générera unpackage.jsonpour gérer les dépendances du projet. - Ensuite, lancez
npm install puppeteerCeci installera Puppeteer qui inclue Chromium, donc ne soyez pas surpris si c’est long. - Enfin, ouvrez le dossier dans votre éditeur de code habituel et créez un fichier
index.jsVous aurez aussi besoin de ces dossiers :screenshotspdfsjsonsi vous suivez mon exemple à la lettre.
Un exemple simple
Maintenant, essayons quelque chose de simple (mais de vraiment cool !) pour vérifier que tout fonctionne correctement. Nous allons prendre une capture d’écran d’une page internet et générer un fichier PDF (oui, c’est simple à faire !).
Pour la plupart de mes exemples, j’utiliserai scrapethissite.com. Vous pouvez utiliser le site que vous voulez tant qu’il vous permet de scraper. Cherchez leur conditions générales d’utilisation et essayez de regarder le fichier robots.txt (pour vérifier que le site autorise les robots ?)
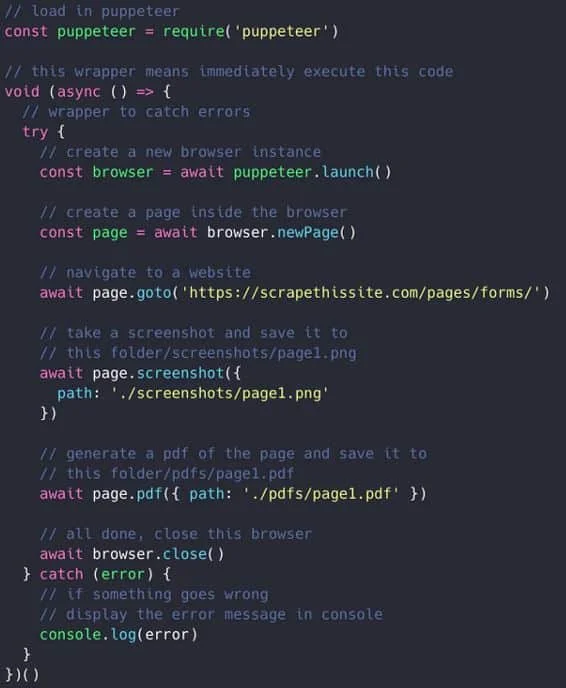
Générer une capture d’écran et un pdf
Ceci correspond à tout le code nécessaire pour démarrer le navigateur headless, aller sur un site, prendre ensuite une capture d’écran et générer le pdf avec.
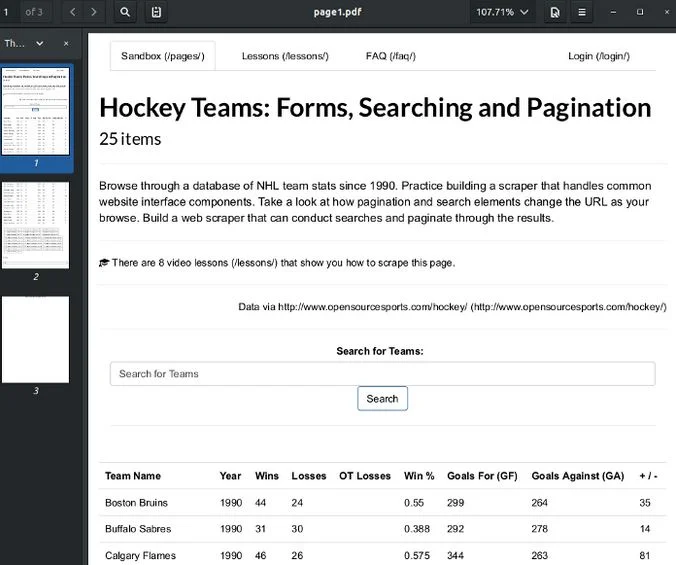
Fichier pdf créé
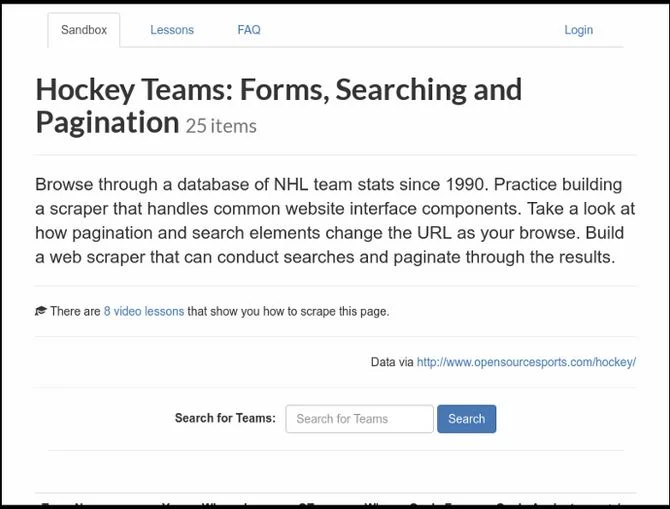
Impression d’écran obtenue
Cliquez ici pour plus d’informations sur les impressions d’écran et ici pour plus d’informations sur la génération de pdf.
Les impressions d’écran et les pdf sont sympas, mais comment ça peut m’aider à obtenir des données plus vite ?
Ces fonctionnalités sont top si vous voulez des pdf et impressions d’écran spécifiques. Quand vous voulez obtenir et avoir la possibilité d’utiliser des données, il y a alors d’autres outils à votre disposition.
Obtenir des données — Préparations
En utilisant le même site que dans l’exemple précédent, nous allons recueillir quelques données et les conserver dans un fichier. Dans ce scénario, imaginons que nous souhaitions juste avoir le nom de l’équipe, l’année de sa constitution, ses victoires et ses défaites. La première étape est de créer quelques sélecteurs.
Un sélecteur est simplement un chemin pour accéder aux données (pensez aux sélecteurs CSS). Bien, passons à l’étape supérieure avec ces chemins d’accès en utilisant les outils développeur de notre navigateur. Ouvrez-les sur la page internet en ouvrant le menu de votre navigateur et en cherchant « outils développeur ». Sur Chrome, vous n’aurez juste qu’à appuyer sur CTRL + Shift + I pour les ouvrir.
Sur le site, ouvrez l’onglet avec la liste des éléments dans l’outils développeur et trouvez quelles données vous voulez obtenir. Notez leur structuration, catégorie, etc.
S’il vous arrive de ne vouloir qu’une seule partie spécifique, alors vous pouvez juste faire un clic droit sur le node et choisir « copier le sélecteur ».
Remarques sur les données que je veux
- Elles sont dans des tableaux
- Les lignes avec les données sur l’équipe sont dans la catégorie appelée
team - Dans
tr.teamil y a plusieurstdavec les noms de catégories :nameyearwinsetlosseslesquelles contiennent les données que je veux.
Mes sélecteurs
Les sélecteurs que j’ai utilisés pour cet exemple sont :
- Ligne pour l’équipe :
tr.team - Données :
teamRow > td.${dataName}( remplacer ${dataName} avec le nom)
Vous pouvez avoir plus d’informations sur les sélecteurs CSS ici si ce terme est nouveau pour vous.
Obtenir des données
Il est l’heure d’appliquer tout cela dans notre code.
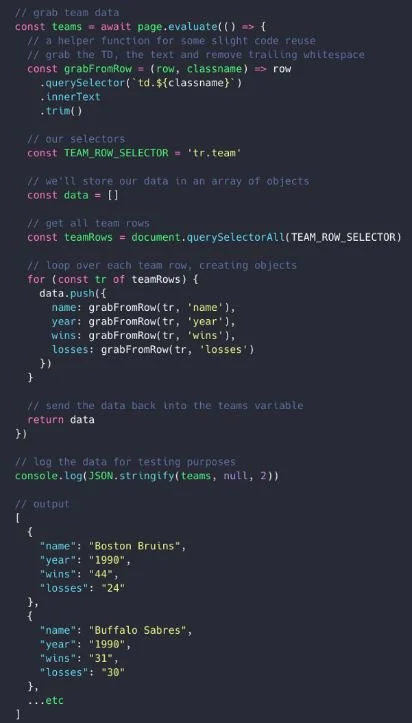
Code pour obtenir les données sur l’équipe
La principale partie ici est page.evaluate(). Elle nous permet de faire fonctionner le code JS dans le navigateur et de récupérer n’importe quelle donnée souhaitée. C’est tout ce qu’il faut pour aller chercher les données.
Vous avez sans doute remarqué que nous avons accès ici au DOM — voici une bien belle API que Puppeteer fournit !
Enregistrer les données dans un fichier
Et voici maintenant la touche finale, la cerise sur le gâteau ! Nous allons enregistrer ces données dans un fichier. Dans mon cas, je veux les données au format JSON parce que c’est plus facilement utilisable en javascript.
- Chargez le module de fichier système depuis node
- Convertissez les données au format JSON avec
JSON.stringify() - Enregistrez le fichier avec
fs.writeFile()
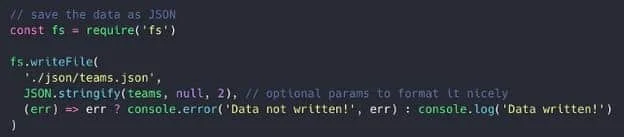
Enregistrement des données sous format JSON
Vous trouverez ici de la documentation sur la plateforme node.js et ici sur la méthode JSON.stringify ( ).
Scraping plus avancé
Puppeteer fonctionne sur tous les sites, complexes ou non comme les applications web SPA (en anglais « Single page applications » ou « SPA » = navigation sans recharger la page), fonctionne avec des données de simulation, permet de faire des tests et bien plus encore. Cela va au-delà du cadre de ce tutoriel, mais vous pouvez trouver des exemples dans la documentation sur Puppeteer (mentionnée plus bas) ainsi que dans cet autre article.
Références et liens
https://developers.google.com/web/updates/2017/04/headless-chrome
https://github.com/GoogleChrome/puppeteer
Vous avez trouvé cet article trop difficile ? Je vous recommande celui-ci. Il parle de la même chose, mais avec plus de détails.
N’hésitez pas à laisser vos remarques et questions en commentaire.
D’autres articles Growth que vous allez aimer ❤️
Nos dernières success stories en growth
Altaroc est une société de gestion française spécialisée dans le private equity, qui offre aux investisseurs privés un accès à des fonds normalement réservés aux institutionnels, dans des secteurs tels que la technologie et la santé. Altaroc a réussi à lever 180 millions d'euros pour son fonds Odyssey, dépassant ainsi de près du double son objectif initial



Chaque semaine, recevez les meilleurs articles growth résumés et découvrez un outil unique pour booster votre business. Profitez aussi d’outils gratuits et de webinars exclusifs.
.avif)
Commentaires